

What is Vulnerability Management?
Well, running a periodic Nessus scan on some of your organisation’s stuff ain’t it.
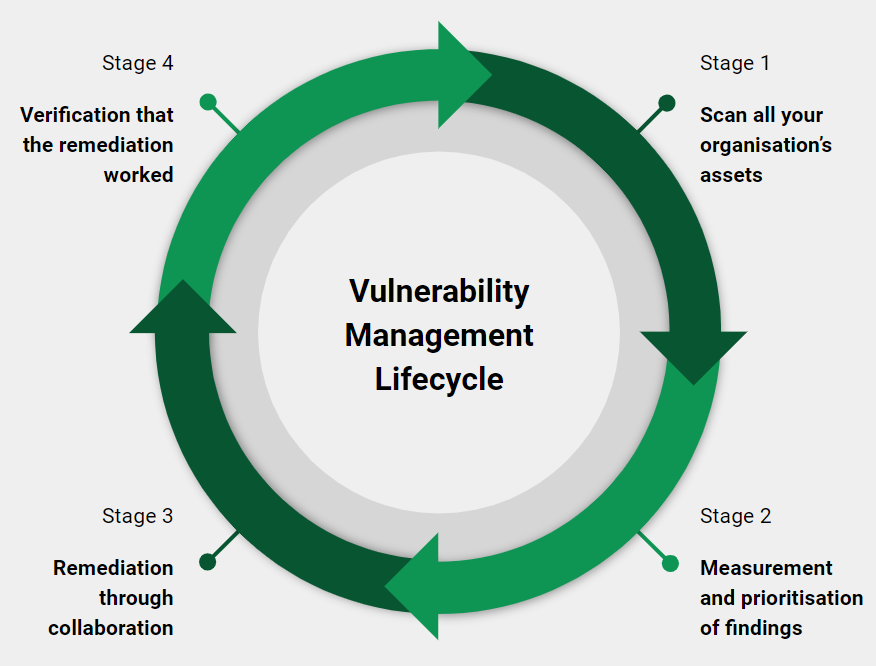
That’s because it’s a full lifecycle of tools, team collaboration and processes, including:
- Periodic/continuous scanning of all your organisation’s assets, using various tools
- Informed measurement and prioritisation of findings from these tools
- The remediation of those findings through collaboration with other teams
The verification that those remediation actions worked
- Extra Bonus Stage - Doing it all again because it’s a continuous virtuous cycle
Without each of these steps, you’ll end up with lots of work and a false sense of security.
 Vulnerability Management Cycle
Vulnerability Management Cycle
This blog post outlines each of these steps and the overarching need for empathy for these programmes to succeed.
Caveat
While I’ve some experience in setting up and running Vulnerability Management programmes, I’m not an expert and generally don’t like that term. If I’ve made any mistakes or omitted anything important I’d love to know. I’m keen to continually learn.
Coverage
This is where I harp on about the importance of IT Asset Management as the foundation for all other InfoSec functions.
If you don’t have clear visibility of all your assets and how they’re being used by your staff and customers, you’ll struggle to secure them.

This should include your organisation’s:
- Endpoint devices
- Mobile devices
- Servers
- Infrastructure components
- Code repositories
- Data centres
- 3rd party vendors
- Internal processes
- The list goes on…
The same principle applies to Vulnerability Management. If you’re only scanning a portion of your assets, you’ll get a false sense of security when a tool or scanner reports that you only have n number of critical vulnerabilities.
For example, if you have 200 assets, scan 20 of them and as a result identify 2 vulnerabilities that might seem ok. But you’re sampling here, so in actuality you could have 20 vulnerabilities in total with 18 going unidentified.
Getting 100% coverage is hard though. It requires a mature IT Asset Management foundation and multiple Vulnerability Management solutions, each fulfilling a different function.
You will unfortunately (most likely) need different Vulnerability Management solutions for different use cases, as each will find vulnerabilities in different parts of your organisation.
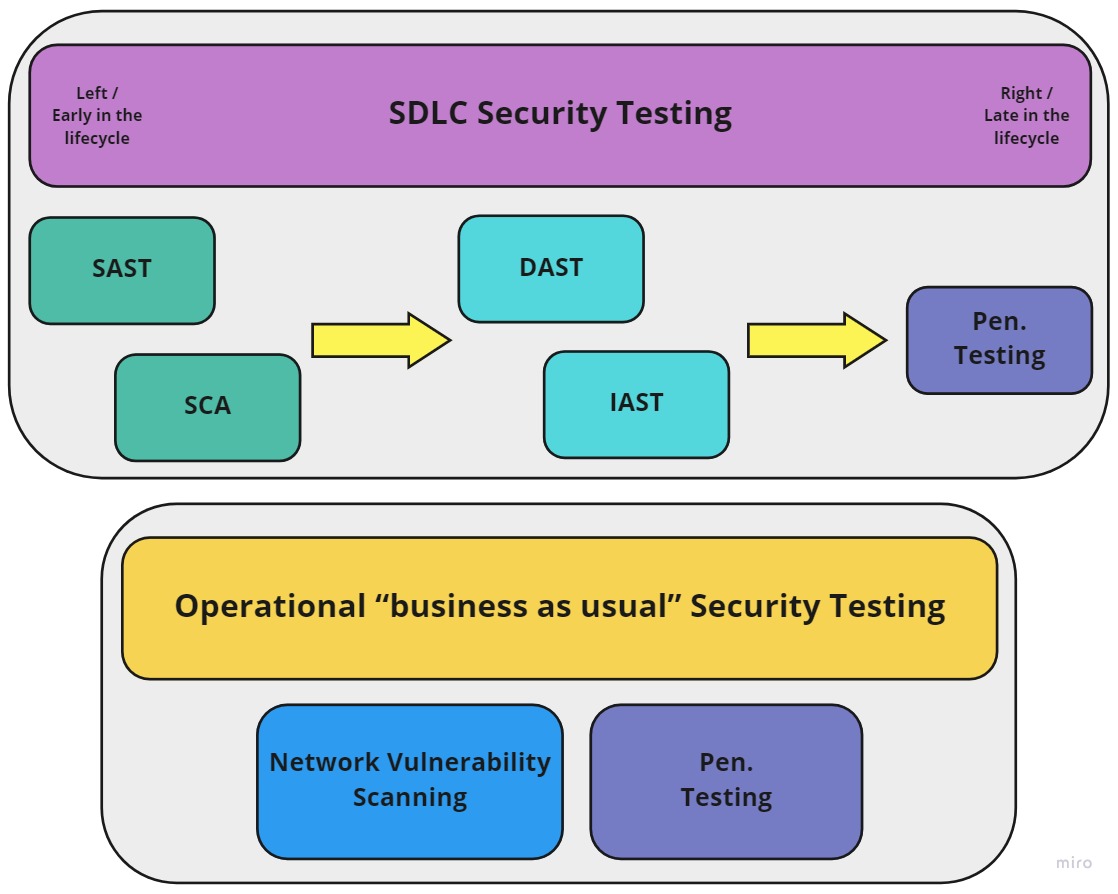
These tools and methods can either be used as a part of the SDLC, to ensure that a deployed product is secure by design, or as an operational “business as usual” service, run by your security assurance team, to find and fix vulnerabilities in deployed assets.
Examples of vulnerability solution types include:
- Static Analysis Security Testing (SAST) solutions
What they do:These search for vulnerabilities in your code base.When they're used:SAST is often used during the early stages of the software development lifecycle (SDLC) and/or through integrating it as an automated step in a deployment pipeline.Examples:OWASP includes a good list of SAST tools here: https://owasp.org/www-community/Source_Code_Analysis_Tools
- Dynamic Analysis Security Testing (DAST) solutions
What they do:These search for vulnerabilities in your applications during runtime (i.e. DAST doesn’t scan source code. Instead it dynamically checks running applications for vulnerabilities).When they're used:As DAST is performed at runtime, it is used later in the SDLC (further right) and is often performed as an automated step in a deployment pipeline.Examples:OWASP ZAP is a full-featured free and open-source DAST tool.
- Software Composition Analysis (SCA) solutions
What they do:These search for vulnerabilities in open-source packages and components that are included or imported into your applications (think Log4J).When they're used:SCA is often used during the early stages of the software development lifecycle (SDLC)Examples:Github & Snyk both include easy to use SCA features.
- Network Vulnerability Scanning solutions
What they do:These scan networks and connected devices/servers for vulnerabilities.When they're used:Network Vulnerability scanners are often used as an operational, “business as usual” service run by an Information Security Assurance team.Examples:OpenVAS is an example of a flexible open-source vulnerability scanner. Nessus, Qualys and Acunetix also fit into this category.Coverage challenges due to the COVID-19 Pandemic:Traditional solutions to identify vulnerabilities on corporate assets (devices, servers and infrastructure) are no longer fit for purpose due to the large amount of remote working, triggered by COVID-19. These solutions relied on assets being connected to the corporate network. Corporate VPN solutions help, but with so many SaaS products using local or single sign-on (SSO) authentication, users are no longer incentivised to continually connect to these VPNs. This results in solutions like Nessus Professional only finding vulnerabilities on a small portion of connected devices. In response to this, the industry is promoting agent-based solutions which can call back to a central vulnerability management service regardless of location or network connection.
- Interactive Application Security Testing (IAST) solutions
What they do:Through installed agents, these test applications at runtime while analysing the relevant source code to identify more vulnerabilities with a lower rate of false positives.When they're used:IAST generally takes place during the test/QA stage of the software development life cycle (SDLC)More Information:DZone has a great article going into further detail about IAST here.
- Penetration (pen.) Testing
What they do:This is an authorised security attack exercise where a pen-tester attempts to actively find and exploit vulnerabilities in an application.When they're used:This occurs in the late stages of the SDLC, or on production systems/applications, as a final test that mimics real world attack methods.Only performing Pen. Testing?For so many reasons, pen. testing shouldn’t be performed in place of all the other methods mentioned above. Firstly, only performing pen. testing will result in those testers finding obvious “low hanging fruit” vulnerabilities. If you caught and addressed these earlier on in the SDLC you would get a lot more value from a pen test as you’ll make them work harder. Also, only performing pen. testing gives management and leadership a false sense of cost savings. Sure, you don’t have to spend time and money performing multiple other security tests, but when a pen. tester finds tonnes of vulnerabilities right before an application is meant to go live, it’s going to cause significant delays which could have been better handled in the earlier stages of the SDLC.
I think the trick is to understand the assets your organisation already has in place and what they’re planning on developing/procuring in the near future. Then you can begin to explore various options to implement Vulnerability Management tooling or processes that fit your organisation’s threats.
Ideally, you’d want to scan everything all the time, but that’s not always very easy. Let’s explore why.
Continuous scanning of everything
Continuously scanning can be really challenging. It requires a lot of oversight and operational management, but that caveat doesn’t change the goal: You want to continually have an up to date picture of the security posture of all your assets. With that full picture, you can prioritise effectively to reduce your organisation’s risk exposure, by addressing business critical, high value and high risk vulnerabilities first.
One thing worth mentioning here is to keep in mind the Load implications of running vulnerability scanning tools continuously. Testing is key here as you’ll need to identify what you can do without breaking your organisation’s technology and processes. Some scans can eat up a lot of bandwidth and resources. It’s recommended that you chat with relevant technical leads, so you don’t end up DoSing your own systems.
My recommendation here is to have a friendly and empathetic chat with your architecture, development, test and operations teams to figure out what will and won’t work for them.
This could include discussions about tooling that works for those teams, while also achieving adequate coverage and an appropriate schedule. Ideally, you don’t want to ask a team to use tools they hate, so instead you could ask them to try a few and see what works for everyone.
Continuous scanning all the time, or every once in a while?
It’s generally not recommended to only scan your assets once a year because you’ll be unaware of all newly introduced vulnerabilities throughout that year and will end up with a long list of things to fix when that scan comes around. But sometimes a periodic scan is the most pragmatic approach. If you can get that period to occur often, like once a month, you’ll get a lot of the same benefits realised through continuous scanning.
Firstly you’ll get the obvious benefit of having good visibility as your assets change over time, but you’ll also keep your architecture, development, test and operations teams happy (after the initial wave of vulnerabilities you find after the first scan 😭).

Instead of sharing a list of thousands of significant vulnerabilities once a year, you can continually work with teams and support them to address findings on an on-going basis. This allows them to bake remediation, configuration updates and patch management practices into their technical backlogs, business as usual workloads and capacity management.
Measurement & Prioritisation
After you run some scans, you’ll realise that you’ve identified a significant number of vulnerabilities. While this can be massively worrying and panic inducing, it’s pretty common to have a tonne of findings when you start looking. Handling this requires some planning to identify which vulnerabilities should be remediated and addressed first.
CVSS scores are incredibly useful in helping organisations to understand and prioritise their vulnerabilities. They are derived from various metrics which can be used to help understand a given score’s relevance in your own context.
“Vulnerability Management doesn’t really work without a mature IT Asset Management programme in place. You can’t prioritise based on CVSS measurements alone.”
Each of the CVSS metrics below are useful in understanding how a given vulnerability might affect your organisation.
The following is a list of metrics used in CVSS v3.1:
Base Score Metrics
| Metric | Score |
|---|---|
| Attack Vector (AV) | Network (AV:N), Adjacent Network (AV:A), Local (AV:L), Physical (AV:P) |
| Attack Complexity (AC) | Low (AC:L), High (AC:H) |
| Privileges Required (PR) | None (PR:N), Low (PR:L), High (PR:H) |
| User Interaction (UI) | None (UI:N), Required (UI:R) |
| Scope (S) | Unchanged (S:U), Changed (S:C) |
Impact Metrics
| Metric | Score |
|---|---|
| Confidentiality Impact (C) | None (C:N), Low (C:L), High (C:H) |
| Integrity Impact (I) | None (I:N), Low (I:L), High (I:H) |
| Availability Impact (A) | None (A:N), Low (A:L), High (A:H) |
Temporal Score Metrics
| Metric | Score |
|---|---|
| Exploit Code Maturity (E) | Not Defined (E:X), Unproven that exploit exists (E:U), Proof of concept code (E:P), Functional exploit exists (E:F), High (E:H) |
| Remediation Level (RL) | Not Defined (RL:X), Official fix (RL:O), Temporary fix (RL:T), Workaround (RL:W), Unavailable (RL:U) |
| Report Confidence (RC) | Not Defined (RC:X), Unknown (RC:U), Reasonable (RC:R), Confirmed (RC:C) |
Environmental Metrics
| Metric | Score |
|---|---|
| Confidentiality Requirement (CR) | None (C:N), Low (C:L), Medium (CR:M), High (C:H) |
| Integrity Requirement (IR) | None (I:N), Low (I:L), Medium (IR:M), High (I:H) |
| Availability Requirement (AR) | None (A:N), Low (A:L), Medium (AR:M), High (A:H) |
CVSS v3.1 includes Environmental Metrics which enable your organisation to customise the CVSS score depending on the importance of the affected IT asset. This allows your organisation to take the business criticality, value and risk associated with a given asset into account when prioritising identified vulnerabilities.
CVSS Shortcomings
However, this requires you to already have an agreed understanding of the business criticality, value and risk of all your assets. The Environmental Metrics of CVSS v3.1 only scratch the surface here. They won’t present you with clear business justifications why a given vulnerability needs to be addressed urgently, due to the criticality (No…this does not equal Availability), value and risk of that asset.
In other words, Vulnerability Management doesn’t really work without a mature IT Asset Management programme in place. You can’t prioritise based on CVSS measurements alone.
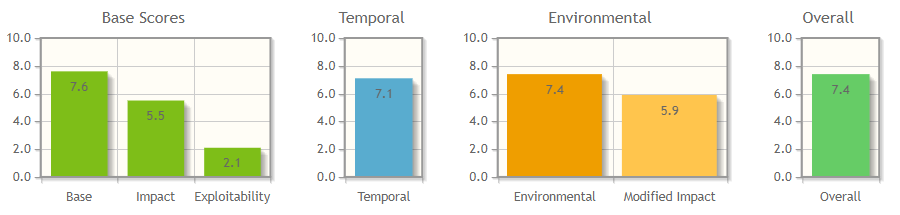
CVSS Score Example:
1
CVSS v3.1 Vector: AV:N/AC:L/PR:L/UI:R/S:U/C:H/I:H/A:L/E:F/RL:O/RC:C/CR:H/IR:H/AR:H/MAV:X/MAC:X/MPR:L/MUI:X/MS:X/MC:X/MI:X/MA:X

Remediation & the need for Engagement & Empathy
When a vulnerability is discovered on an asset, InfoSec teams, 99% of the time, are not the people doing the remediation work (patching/upgrading/reconfiguring). This means they need to work closely with architecture, development, test and operations teams in the hopes that they will fix the issues you’ve found.
But we’ve the same issue here that helped to spawn the DevOps movement: Just as development and operations teams previously didn’t work well together, InfoSec teams often continue to lack empathy and don’t collaborate well with other teams. We are sometimes the “no” team and in relation to identified vulnerabilities, we often recommend “patching” as our one size fits all treatment plan. Lots of the talk and work in and around DevSecOps has been about tooling and integration, but it lacks the collaborative and empathetic successes of the DevOps movement.
This is commonly due to a lack of understanding. For those InfoSec professionals who’ve never worked as developers, testers, system administrators or in an operations team, their only interaction with patching and upgrading will have been through end-user, commercially available software updates.
Here, all the behind the scenes development, configuration work, testing and change advisory boards and documentation (the list goes on) is completed and all you need to do is press the big update button. Even when running a simple server, with a single function and with little integration with its surrounding environment, patching is not a simple task that can occur without care and consideration. It comes with its own IT operational and availability (remember that old chestnut from the CIA triad?) risks that InfoSec teams need to demonstrate empathy and understanding towards. Often a patch or update doesn’t exist yet and the only option is a configuration change or the implementation of compensating security controls, while accepting the residual risk. And using compensating controls will always introduce complexity and an operational cost that will need to be managed.
InfoSec teams should also understand that architecture, development, test and operations teams will already have long product and technical backlogs. Adding something new and expecting it to trump all the other stuff isn’t grounded in reality.
Instead, we need to build bridges with these teams through shared understanding. Not just through rephrasing InfoSec jargon, but through learning their craft, challenges, and values and adapting our tooling/processes/people to fit their needs. We need pragmatism in our interactions and expectations of these teams. We should support and stand up for these teams in our organisations for all the hard work they do.
Verification and Continuous Improvement
While this is a big topic, it can be boiled down to a few simple ideas.
After the development, test and operations teams have remediated a vulnerability, it’s the InfoSec team’s responsibility to then verify that it’s been fixed.
The easiest way to do this is to re-run the original test or scan.
Ideally, this should be done as an embedded part of the vulnerability remediation process, but rechecking for vulnerabilities should also occur through the continuous scanning of all your assets (I think that dead horse is thoroughly flogged now).
If a fix hasn’t worked and your re-scan still shows an active vulnerability, there’s probably a good reason and we should continue to work empathetically with other teams to resolve this.
Conclusion
The key takeaways from this blog are that:
- Comprehensive coverage through asset management is necessary for vulnerability assessment to be meaningful
- Continuous vulnerability scanning comes with its own challenges and it is important to find the right cadence while acknowledging both your risk appetite and your teams’ capacity for remediation
- Having a transparent methodology for measurement and prioritisation of vulnerabilities can help communication and engagement with other teams
- Building a good working relationship with the teams you are engaged with is fundamental so you can have an open dialogue to find the best solution for remediation, be that patching or otherwise. Architecture, development, test and operations teams are friends and should be treated with respect for helping to fix the issues that you’ve found. Don’t be mean
- Vulnerability analysis should be reflexive - it is important to analyse your assumptions, the process and the methodology so you’re not missing key risks